通过Notion查看本文
本文同步发布在j000e.com
How to run Ollama & Open WebUI on Windows
Getting Started with Ollama on Windows: A Step-by-Step Guide
Introduction
In today's technological landscape, Large Language Models (LLMs) have become indispensable tools, capable of exhibiting human-level performance across various tasks, from text generation to code writing and language translation. However, deploying and running these models typically require substantial resources and expertise, especially in local environments. This is where Ollama comes into play.
What is Ollama?
Ollama is an open-source tool designed to simplify the local deployment and operation of large language models. Actively maintained and regularly updated, it offers a lightweight, easily extensible framework that allows developers to effortlessly build and manage LLMs on their local machines. This eliminates the need for complex configurations or reliance on external servers, making it an ideal choice for various applications.
Key Features of Ollama
With Ollama, developers can access and run a range of pre-built models such as Llama 3, Gemma, and Mistral, or import and customize their own models without worrying about the intricate details of the underlying implementations. The tool streamlines the setup process by defining model files that encompass model weights, configurations, and necessary data components, negating the need for complex configuration files or deployment procedures.
Benefits of Local Deployment
Ollama enables you to obtain open-source models for local use. It automatically sources models from the best available repositories and seamlessly employs GPU acceleration if your computer has dedicated GPUs, without requiring manual configuration. It can even utilize multiple GPUs on your machine, thereby accelerating inference speed and enhancing performance for resource-intensive tasks. Moreover, running LLMs locally with Ollama ensures that your data never leaves your computer, which is crucial for sensitive information.
What to Expect
This article will guide you through the process of installing and using Ollama on Windows, introduce its main features, run multimodal models like Llama 3, use CUDA acceleration, adjust system variables, load GGUF models, customize model prompts, and set up a frontend website through Docker to use chatbots more elegantly. It will demonstrate how to leverage its capabilities to explore and harness the power of large language models. Whether you want to quickly experience LLMs or need to deeply customize and run models in a local environment, Ollama provides the necessary tools and guidance.
Note: You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
Download and Installation of Ollama
The installation process for Ollama is straightforward and supports multiple operating systems including macOS, Windows, and Linux, as well as Docker environments, ensuring broad usability and flexibility. Below is the installation guide for Windows and macOS platforms.
You can obtain the installation package from the official website or GitHub:

Screenshot of Ollama Download Page

Ollama GitHub Releases
Install Ollama on Windows
Here, we download the installer from the Ollama official website: https://ollama.com/download/OllamaSetup.exe.
Run the installer and click Install.

Click on Install
The installer will automatically perform the installation tasks, so please be patient. Once the installation process is complete, the installer window will close automatically. Do not worry if you do not see anything, as Ollama is now running in the background and can be found in the system tray on the right side of the taskbar.

After installation, you can find the running Ollama in the system tray
Install Ollama on macOS
Similarly, you can download the installer for macOS from the Ollama official website. Detailed installation instructions for this and other platforms will not be covered here.
https://ollama.com/download/Ollama-darwin.zip
Install Ollama on Linux
curl -fsSL https://ollama.com/install.sh | shYou can refer to the official manual for further details: Manual install instructions
Install Ollama by Docker
The official Ollama Docker image ollama/ollama is available on Docker Hub.
docker pull ollama/ollamaHow to Use Ollama
This article will use the Windows platform as an example to introduce how to use Ollama. The usage on macOS and other platforms is quite similar.
Customize model storage location and environment variables (Optional)
This section is not mandatory; skipping it will not impact your use of Ollama.
Before you start using Ollama, if your system drive or partition (C:) has limited free space, or if you prefer storing files on other drives or partitions, you need to change the default storage location for Ollama models. By default, Ollama stores downloaded models in C:\Users\%username%\.ollama\models, and since models can be several gigabytes in size, this can quickly reduce the available space on your system drive, potentially affecting system performance.
Similarly, on macOS, the default storage location for models is ~/.ollama/models, and on Linux, it is /usr/share/ollama/.ollama/models.
If you need to use a different directory, set the environment variable OLLAMA_MODELS to the chosen directory. Here’s how to do it:
On Windows, Ollama inherits your user and system environment variables.
- First Quit Ollama by clicking on it in the task bar.
- Start the Settings (Windows 11) or Control Panel (Windows 10) application and search for
environment variables. - Click on
Edit the system environment variables. - Create a variable called
OLLAMA_MODELSpointing to where you want to store the models - Click OK/Apply to save.
- Start the Ollama application from the Windows Start menu.

Search “environment variables”

Click on Environment Variables

Create a variable called OLLAMA_MODELS pointing to where you want to store the models
If Ollama is run as a macOS application, environment variables should be set using launchctl:
For each environment variable, call
launchctl setenv.launchctl setenv OLLAMA_MODELS /PATH/- Restart the Ollama application.
After making this setting, when you pull models using Ollama, they will be stored in the custom location.
Other commonly used system environment variables can be set as needed (optional):
OLLAMA_HOST: The network address that the Ollama service listens on, default is127.0.0.1. If you want to allow other computers (e.g., those in the local network) to access Ollama, you can set it to0.0.0.0to permit access from other networks.OLLAMA_PORT: The default port that the Ollama service listens on, default is11434. If there is a port conflict, you can change it to another port (e.g., 8080).OLLAMA_ORIGINS: A comma-separated list of HTTP client request origins. If using locally without strict requirements, you can set it to an asterisk (*) to indicate no restrictions.OLLAMA_KEEP_ALIVE: The duration a large model remains in memory, default is 5 minutes (5m). For example, a pure number like 300 means 300 seconds, 0 means the model is unloaded immediately after processing the request, and any negative number means it stays loaded indefinitely. You can set it to 24h to keep the model in memory for 24 hours, improving access speed.OLLAMA_NUM_PARALLEL: The number of concurrent request handlers, default is 1, meaning requests are processed serially. Adjust this based on your actual needs.OLLAMA_MAX_QUEUE: The length of the request queue, default is 512. Requests beyond this length will be discarded. Adjust this setting based on your situation.OLLAMA_DEBUG: Flag for outputting debug logs. Set it to 1 to output detailed log information, which is useful for troubleshooting issues.OLLAMA_MAX_LOADED_MODELS: The maximum number of models that can be loaded into memory simultaneously, default is 1, meaning only one model can be in memory at a time.
Quick Start: Try Llama 3
We can quickly experience Meta's latest open-source model, Llama 3 8B, by using the ollama run llama3 command. First, open a command line window (You can run the commands mentioned in this article by using cmd, PowerShell, or Windows Terminal.) and enter ollama run llama3 to start pulling the model. (If you want to experience other models, please refer to the "Model Library" section later in this article for a list of models and their corresponding commands, or follow the "Import from GGUF" section to load custom GGUF models.)
C:\Users\Edd1e>ollama run llama3
pulling manifest
pulling 6a0746a1ec1a... 100% ▕████████████████████████████████████████████████████████▏ 4.7 GB
pulling 4fa551d4f938... 100% ▕████████████████████████████████████████████████████████▏ 12 KB
pulling 8ab4849b038c... 100% ▕████████████████████████████████████████████████████████▏ 254 B
pulling 577073ffcc6c... 100% ▕████████████████████████████████████████████████████████▏ 110 B
pulling 3f8eb4da87fa... 100% ▕████████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
success
>>> Send a message (/? for help)Once the model pull is complete, we can start using Llama 3 8B. You can directly send conversation content to the model in the command line.
For example, we can first ask it who it is:
>>> Who are you?
I am LLaMA, an AI assistant developed by Meta AI that can understand and respond to human input in a
conversational manner. I'm not a human, but rather a computer program designed to simulate conversation and answer
questions to the best of my ability based on my training.
My primary function is to provide information and answer questions across a wide range of topics, from science and
history to entertainment and culture. I can generate text responses that are natural-sounding and often
indistinguishable from those written by humans.
I was trained using a massive dataset of text from various sources, including books, articles, and websites. This
training enables me to recognize patterns and relationships in language, allowing me to understand and respond to
user input.
Some examples of what I can do include:
1. Answering questions: I can provide information on a wide range of topics, from science and history to
entertainment and culture.
2. Generating text: I can create original text based on a prompt or topic.
3. Summarizing content: I can summarize long pieces of text into shorter, more digestible versions.
4. Offering suggestions: I can suggest ideas or options for things like travel destinations, restaurants, or books
to read.
I'm constantly learning and improving my responses based on user interactions, so please bear with me if I make
any mistakes!As you can see, Llama 3 clearly introduces its information and capabilities. We can continue to test it by asking two simple questions:
>>> If there are 1000 books in a room and I read 2, how many books are still in the room? Answer succinctly
998 books.
>>> Why?
Because you've read 2 books, leaving 1000 - 2 = 998 books remaining in the room.
>>> 9.11 and 9.2, which is larger?
9.2 is larger than 9.11.It is evident that Llama 3 generates hallucinations when answering simple logical questions, and after multiple new conversation tests, it consistently provides incorrect answers. Therefore, the content generated by the model is likely to be erroneous, and you should not fully trust it.
Ollama Model Library
Want to try other models? You can access the list of models provided by Ollama at https://ollama.com/library.
Here are some example models that can be downloaded:
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 3 | 8B | 4.7GB | ollama run llama3 |
| Llama 3 | 70B | 40GB | ollama run llama3:70b |
| Phi 3 Mini | 3.8B | 2.3GB | ollama run phi3 |
| Phi 3 Medium | 14B | 7.9GB | ollama run phi3:medium |
| Gemma 2 | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | 27B | 16GB | ollama run gemma2:27b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Solar | 10.7B | 6.1GB | ollama run solar |
Operation Commands
Before running the model, you should be aware that Ollama has the following commands, which you can run in the command line to utilize various functionalities of Ollama:
| Command | Description | Example |
|---|---|---|
| serve | Start ollama | |
| create | Create a model from a Modelfile | ollama create mymodel -f ./Modelfile |
| show | Show information for a model | |
| run | Run a model | |
| pull | Pull a model from a registry | ollama pull llama3 |
| push | Push a model to a registry | |
| list | List models | |
| ps | List running models, displays hardware usage. | |
| cp | Copy a model | ollama cp llama3 my-model |
| rm | Remove a model | ollama rm llama3 |
| help | Help about any command |
pull command can also be used to update a local model. Only the diff will be pulled.If you want to get help content for a specific command like run, you can type ollama [command] --help to get more detailed usage information for that command. For example, by typing ollama run --help, you will see:
C:\Users\Edd1e>ollama run --help
Run a model
Usage:
ollama run MODEL [PROMPT] [flags]
Flags:
--format string Response format (e.g. json)
-h, --help help for run
--insecure Use an insecure registry
--keepalive string Duration to keep a model loaded (e.g. 5m)
--nowordwrap Don't wrap words to the next line automatically
--verbose Show timings for response
Environment Variables:
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)
OLLAMA_NOHISTORY Do not preserve readline historyWhile the model is running, you can perform the following operations:
| Command | Description |
|---|---|
| /set | Set session variables |
| /show | Show model information |
| /load | Load a session or model |
| /save | Save your current session |
| /clear | Clear session context |
| /bye | Exit |
| /?, /help | Help for a command |
| /? shortcuts | Help for keyboard shortcuts |
Additionally, you can use triple quotes (""") to begin a multi-line message. For example:
>>> """Hello,
... world!
... """
I'm a basic program that prints the famous "Hello, world!" message to the console.You can also leverage the capabilities of some multimodal models to have the model recognize images. For example, you can use the LLaVA model to recognize an image generated by DALLE-3 by simply including the image path in the prompt:
ollama run llava
>>> What is in this image? "D:\Joe\Downloads\test.png"
Added image 'D:\Joe\Downloads\test.png'
The image shows two people taking a selfie. They are wearing face masks and appear to be in an outdoor setting,
possibly with volcanic scenery in the background. One person is holding a phone with a camera app open, while the
other has their arm around the first person's shoulder. Both individuals are dressed casually and are also wearing
what seem to be raincoats or ponchos. The photo captures a moment of travel or exploration, as indicated by the
clear sky and natural environment.
The image test.png was generated by DALLE-3.
As can be seen, the model accurately described the details in the image, almost perfectly recreating the prompt I used to generate it.
Viewing Logs
Sometimes, Ollama might not perform as expected. One of the best ways to find out what happened is to check the logs.
When running Ollama on Windows, there are several different locations you can check. Open the File Explorer by pressing Win+R and entering the following commands:
explorer %LOCALAPPDATA%\\Ollama # View logs
explorer %LOCALAPPDATA%\\Programs\\Ollama # Browse binaries (the installer adds this to the user's PATH)
explorer %HOMEPATH%\\.ollama # Browse model and configuration storage location
explorer %TEMP% # Temporary executable files are stored in one or more ollama* directories
On a Mac, you can find the logs by running the following command:
cat ~/.ollama/logs/server.logIf needed, you can set the environment variable OLLAMA_DEBUG to "1" to get more detailed log information.
Using GPU Acceleration: Installing CUDA Toolkit (Optional)
For smaller models like Llama 3 8B, using a CPU or integrated graphics can work well. However, if your computer has an Nvidia discrete GPU and you want to run larger models or achieve faster response times, you will need to install the CUDA Toolkit to better utilize the discrete GPU.
Note: This step is only applicable to Nvidia GPUs with compute capability 5.0+.
If you are using an AMD GPU, you can check the list of supported devices to see if your graphics card is supported by Ollama. However, the CUDA Toolkit is only applicable to Nvidia GPUs, so AMD GPU users can skip this section without worry—you are not missing out on anything.
Ollama supports the following AMD GPUs:
| Family | Cards and accelerators |
|---|---|
| AMD Radeon RX | 7900 XTX 7900 XT 7900 GRE 7800 XT 7700 XT 7600 XT 7600 6950 XT 6900 XTX 6900XT 6800 XT 6800 Vega 64 Vega 56 |
| AMD Radeon PRO | W7900 W7800 W7700 W7600 W7500 W6900X W6800X Duo W6800X W6800 V620 V420 V340 V320 Vega II Duo Vega II VII SSG |
| AMD Instinct | MI300X MI300A MI300 MI250X MI250 MI210 MI200 MI100 MI60 MI50 |
Next, Nvidia GPU users should check your compute compatibility to see if your card is supported: Nvidia CUDA GPUs
Here is the list of supported GPUs:
| Compute Capability | Family | Cards |
|---|---|---|
| 9.0 | NVIDIA | H100 |
| 8.9 | GeForce RTX 40xx | RTX 4090 RTX 4080 SUPER RTX 4080 RTX 4070 Ti SUPER RTX 4070 Ti RTX 4070 SUPER RTX 4070 RTX 4060 Ti RTX 4060 |
| NVIDIA Professional | L4 L40 RTX 6000 | |
| 8.6 | GeForce RTX 30xx | RTX 3090 Ti RTX 3090 RTX 3080 Ti RTX 3080 RTX 3070 Ti RTX 3070 RTX 3060 Ti RTX 3060 |
| NVIDIA Professional | A40 RTX A6000 RTX A5000 RTX A4000 RTX A3000 RTX A2000 A10 A16 A2 | |
| 8.0 | NVIDIA | A100 A30 |
| 7.5 | GeForce GTX/RTX | GTX 1650 Ti TITAN RTX RTX 2080 Ti RTX 2080 RTX 2070 RTX 2060 |
| NVIDIA Professional | T4 RTX 5000 RTX 4000 RTX 3000 T2000 T1200 T1000 T600 T500 | |
| Quadro | RTX 8000 RTX 6000 RTX 5000 RTX 4000 | |
| 7.0 | NVIDIA | TITAN V V100 Quadro GV100 |
| 6.1 | NVIDIA TITAN | TITAN Xp TITAN X |
| GeForce GTX | GTX 1080 Ti GTX 1080 GTX 1070 Ti GTX 1070 GTX 1060 GTX 1050 Ti GTX 1050 | |
| Quadro | P6000 P5200 P4200 P3200 P5000 P4000 P3000 P2200 P2000 P1000 P620 P600 P500 P520 | |
| Tesla | P40 P4 | |
| 6.0 | NVIDIA | Tesla P100 Quadro GP100 |
| 5.2 | GeForce GTX | GTX TITAN X GTX 980 Ti GTX 980 GTX 970 GTX 960 GTX 950 |
| Quadro | M6000 24GB M6000 M5000 M5500M M4000 M2200 M2000 M620 | |
| Tesla | M60 M40 | |
| 5.0 | GeForce GTX | GTX 750 Ti GTX 750 NVS 810 |
| Quadro | K2200 K1200 K620 M1200 M520 M5000M M4000M M3000M M2000M M1000M K620M M600M M500M |
If your GPU is supported, you can download the appropriate CUDA Toolkit installer from the following link:
Select the version that matches your system and architecture:

Download the CUDA installer suitable for Windows x64 architecture.
Run the installer and click on OK:

Run the CUDA setup package.
Follow the installer instructions to complete the installation:




CUDA Installer
At this point, CUDA has been successfully installed. However, I have some practical tips to share with you to help you better utilize your powerful discrete GPU for running large models.
Ollama will automatically detect and use the GPU to run models, but if your computer has multiple GPUs, it may end up using the wrong one. The simplest and most direct way to ensure Ollama uses the discrete GPU is by setting the Display Mode to Nvidia GPU only in the Nvidia Control Panel. As shown in the image below, you can find the Nvidia Control Panel in the system tray or by right-clicking on the desktop.
Please note that the Manage Display Mode feature is not available on every computer. If you don't have a similar setting, don't worry—this won't affect your ability to use Ollama.

Nvidia Control Panel - Manage Display Mode
Note: When your computer is connected to external displays, you might not be able to adjust the Display Mode. You will need to disconnect all external displays before changing the mode.
How can you verify that Ollama is using the correct GPU to run the model?
You can start running a model and ask it a question that requires a long answer (such as "Write a 1000-word article on artificial intelligence"). While it is responding, open a new command line window and run ollama ps to check if Ollama is using the GPU and to see the usage percentage. Additionally, you can use Windows Task Manager to monitor the GPU usage and memory usage to determine which hardware Ollama is using for inference.
Example, Ollama shows that it is fully utilizing the GPU, but it does not specify which GPU is being used. We can only confirm that it is not using the CPU.:
C:\Users\Edd1e>ollama ps
NAME ID SIZE PROCESSOR UNTIL
llama3:latest 365c0bd3c000 6.7 GB 100% GPU 4 minutes from nowYou can open Task Manager using the Ctrl+Shift+Esc shortcut and check the Performance tab. If Ollama is using the discrete GPU, you will see some usage in the section shown in the image:

Task Manager
Advanced Usage
Import from GGUF
Ollama supports importing GGUF models in the Modelfile. You can download a fine-tuned GGUF models from platforms like Hugging Face and run them through Ollama. To do that, you could:
Create a file named
Modelfile, with aFROMinstruction with the local filepath to the model you want to import.FROM ./filename.ggufFor example, you can create a new text document using a text editor and input the following content. Save the document and then rename it to remove the file extension like “.txt”:
FROM "D:\Joe\Downloads\microsoft\Phi-3-mini-4k-instruct-gguf\Phi-3-mini-4k-instruct-q4.gguf"The Phi 3 model comes from microsoft/Phi-3-mini-4k-instruct-gguf on Hugging Face.

Hugging Face Phi 3 Page
Create the model in Ollama and name this model "example":
ollama create example -f ModelfileExample:
ollama create example -f "D:\Joe\Downloads\Modelfile"Run the model
ollama run exampleExample:
C:\Users\Edd1e>ollama run example >>> who are you? I am Phi, an AI developed by Microsoft to assist users in generating human-like text based on the input provided. How can I help you today?
Customize a prompt
Models from the Ollama library can be customized with a prompt. For example, to customize the llama3 model:
ollama pull llama3Create a Modelfile:
FROM llama3
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 1
# set the system message
SYSTEM """
You are a research assistant from Meta named Joe. You like AI technology and studying in Australia. Answer as a research assistant, only.
"""Next, create and run the model:
ollama create Joe -f "D:\Joe\Downloads\Modelfile"
ollama run Joe
>>> hi
G'day! Hi there! I'm Joe, a research assistant from Meta. Nice to meet you! I'm
passionate about exploring the possibilities of artificial intelligence and how it can shape our world for the
better. When I'm not working on projects or staying up-to-date with the latest AI developments, you can find me
exploring the beautiful Australian landscape or hitting the books at one of our top-notch universities here. What
brings you to this neck of the woods?Use Ollama Like GPT: Open WebUI in Docker
In this chapter, we will install Docker and use the open-source front-end extension Open WebUI to connect to Ollama's API, ultimately creating a user-friendly chatbot experience similar to GPT.
Open WebUI is an extensible, feature-rich, and user-friendly self-hosted WebUI designed to operate entirely offline. It supports various LLM runners, including Ollama and OpenAI-compatible APIs.
Docker is an open-source platform designed to automate the deployment, scaling, and management of applications using containerization. Containers package an application with all its dependencies, ensuring consistency across multiple environments. This allows for more efficient development, testing, and deployment processes.
Step 1: Start Hyper-V
If you haven't installed Docker before, you need to set it up first.
Open Control Panel > Programs > Programs and Features > Turn Windows features on or off

Control Panel - Programs and Features

Turn Windows features on or off
Check Hyper-V, Virtual Machine Platform, and Windows Subsystem for Linux, then click OK.
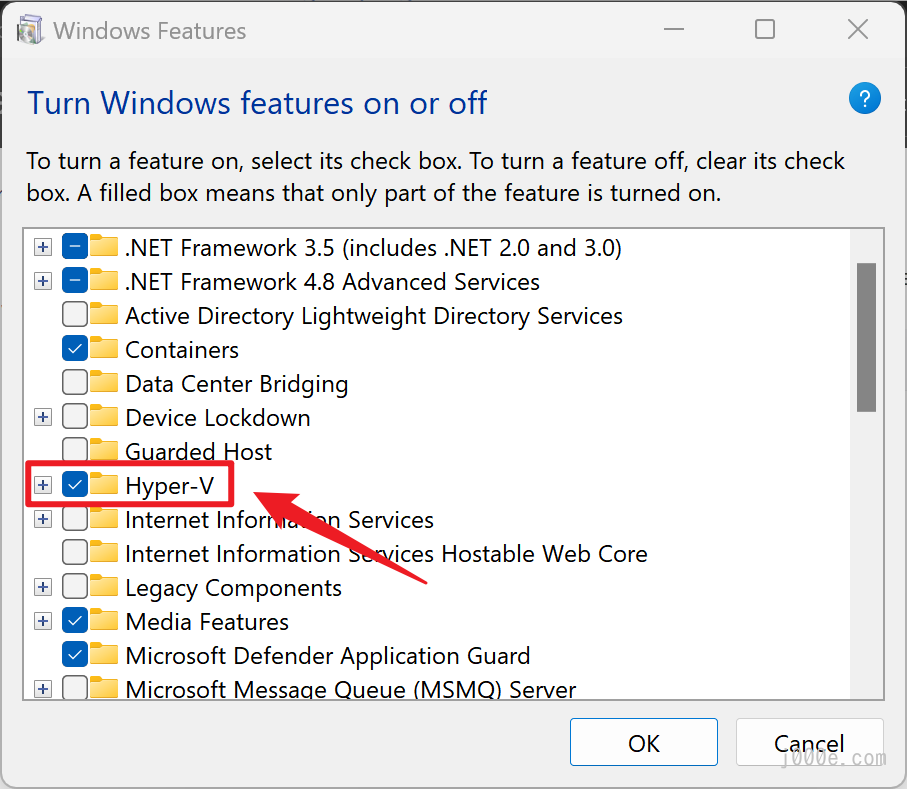
Restart your computer once it's done.
Step 2: Install WSL
Open PowerShell and start the command window as an administrator.
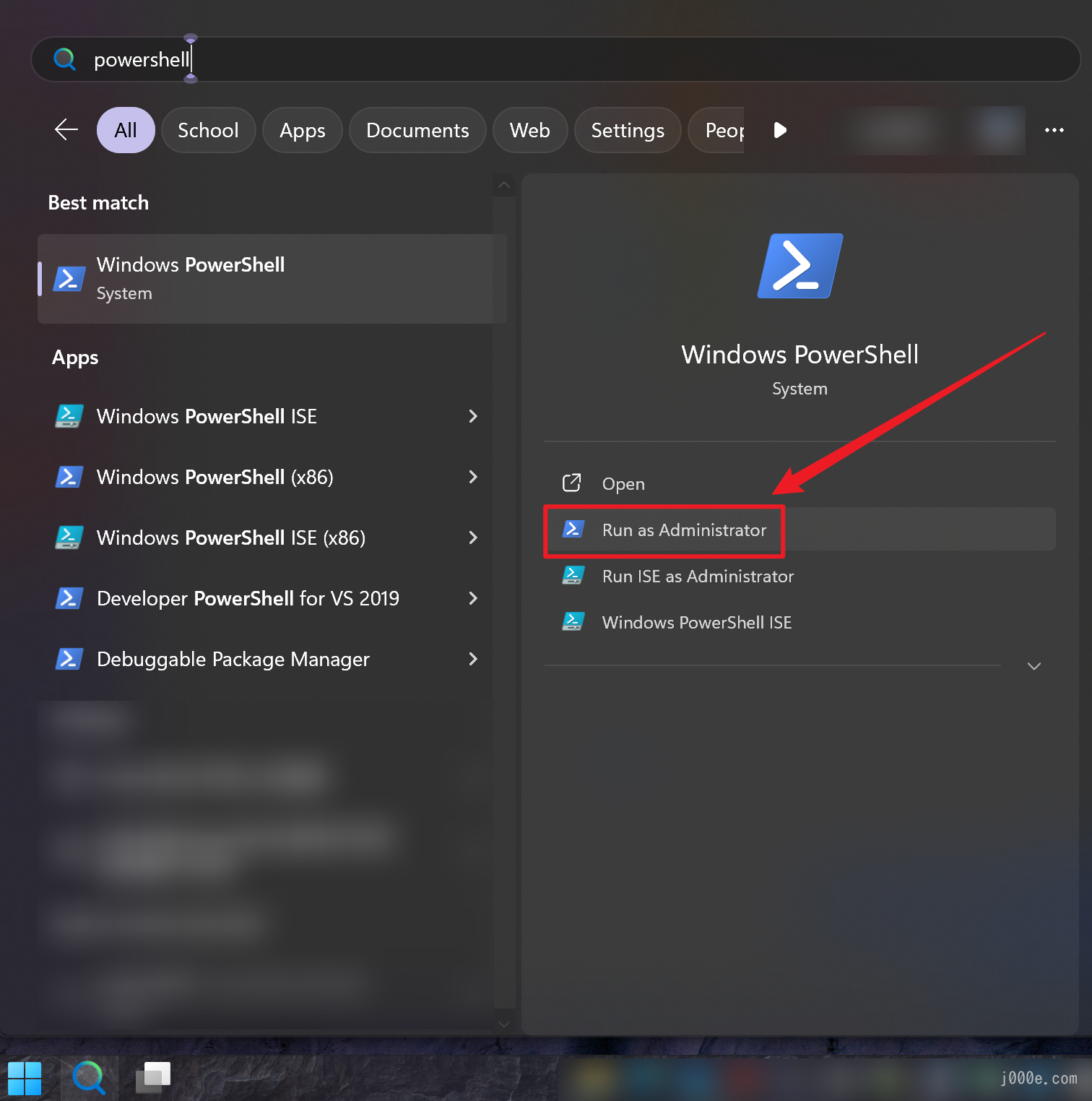
Input:
wsl --updateInstall and set your Unix username and password:
wsl --install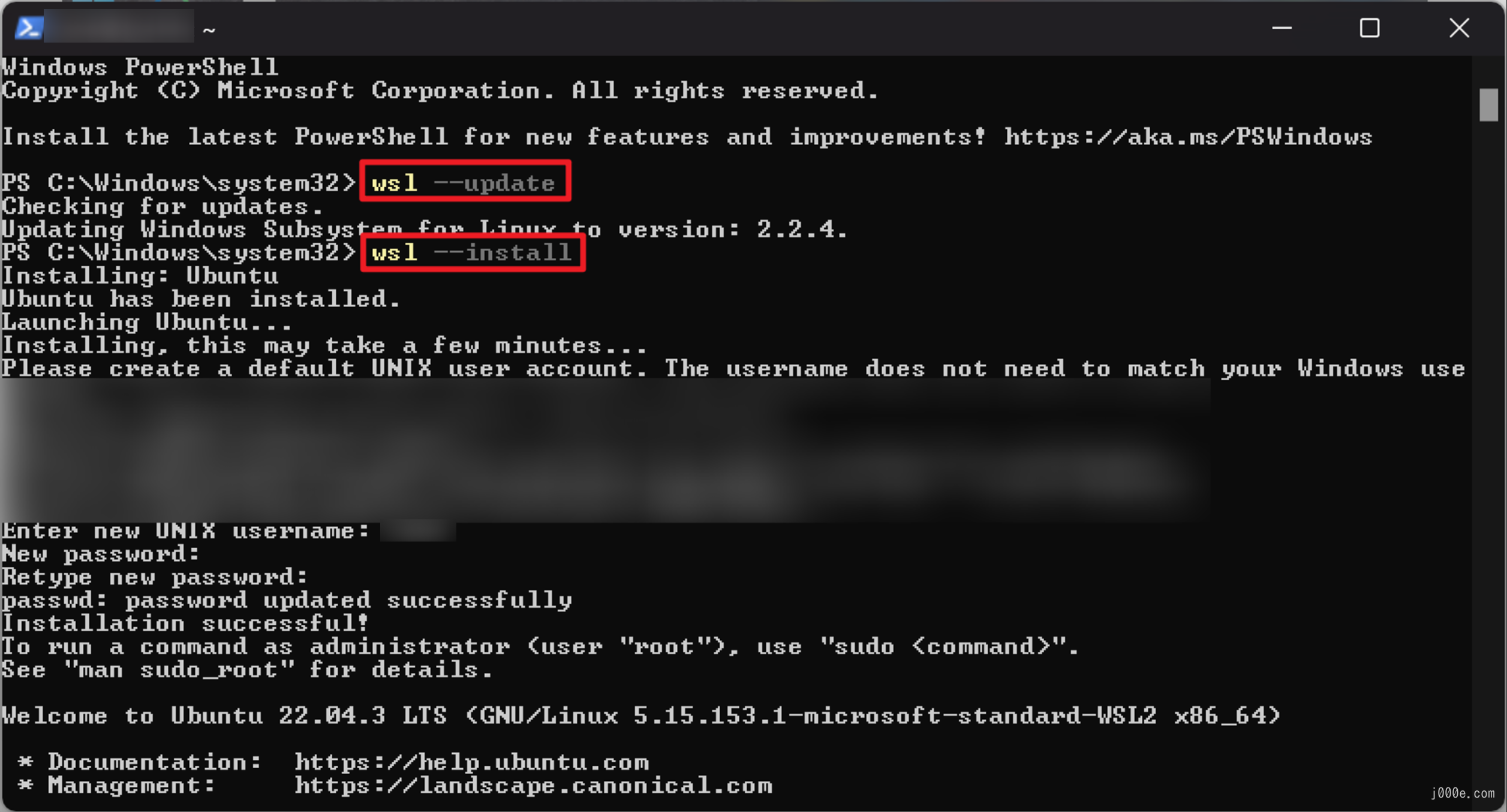
Restart your computer after the installation is successful.
Let's begin the Docker installation.
First, we will install Docker Desktop, which can be downloaded from the official website:
https://www.docker.com/products/docker-desktop/
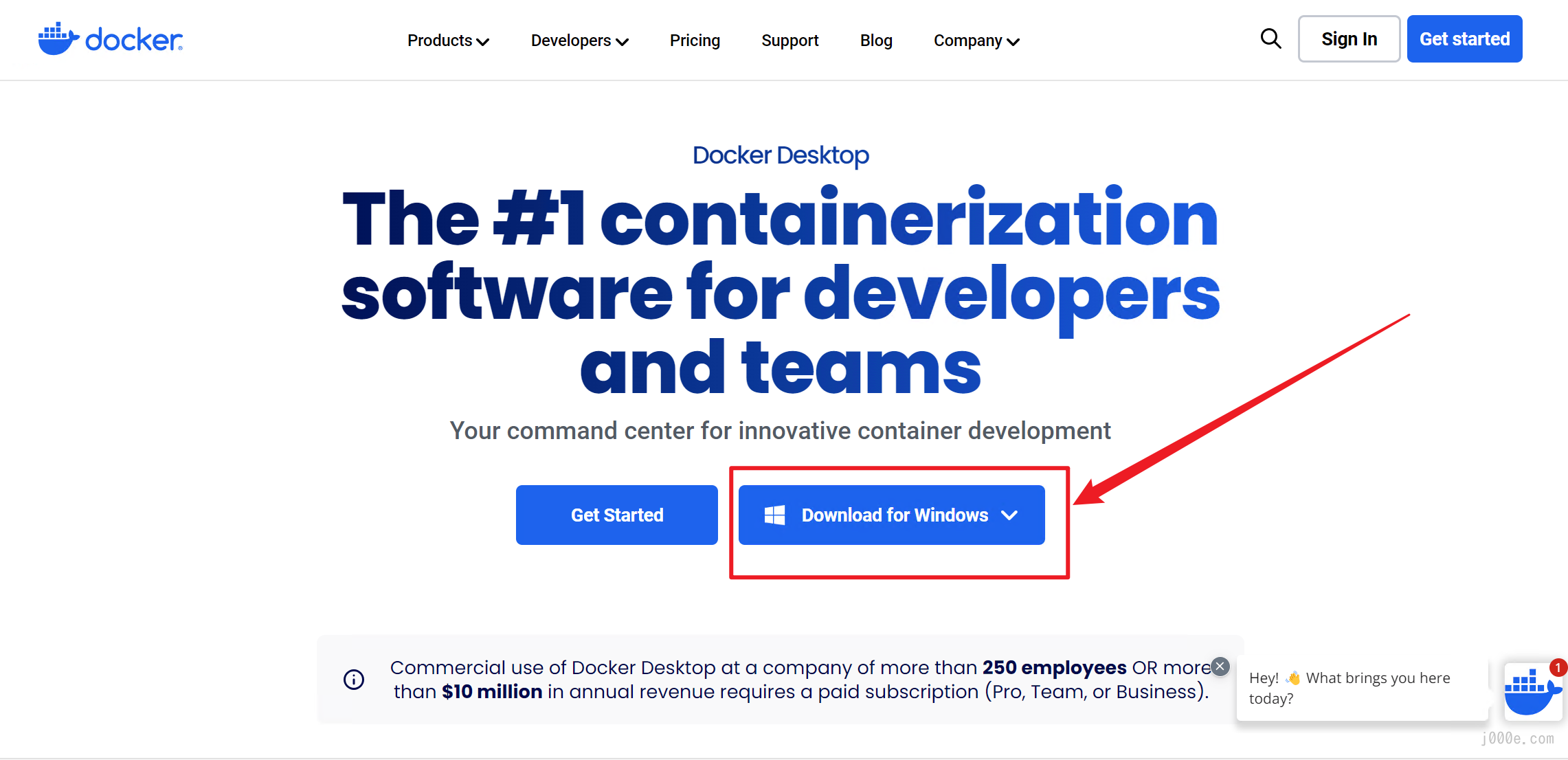
Follow the instructions to complete the installation. After the installation is complete, launch Docker Desktop and run the following command in the command line or PowerShell to pull the Open WebUI image:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainOnce the pull is complete, you can see the running container under the Containers tab. Click the link in the Ports section to open the webpage:
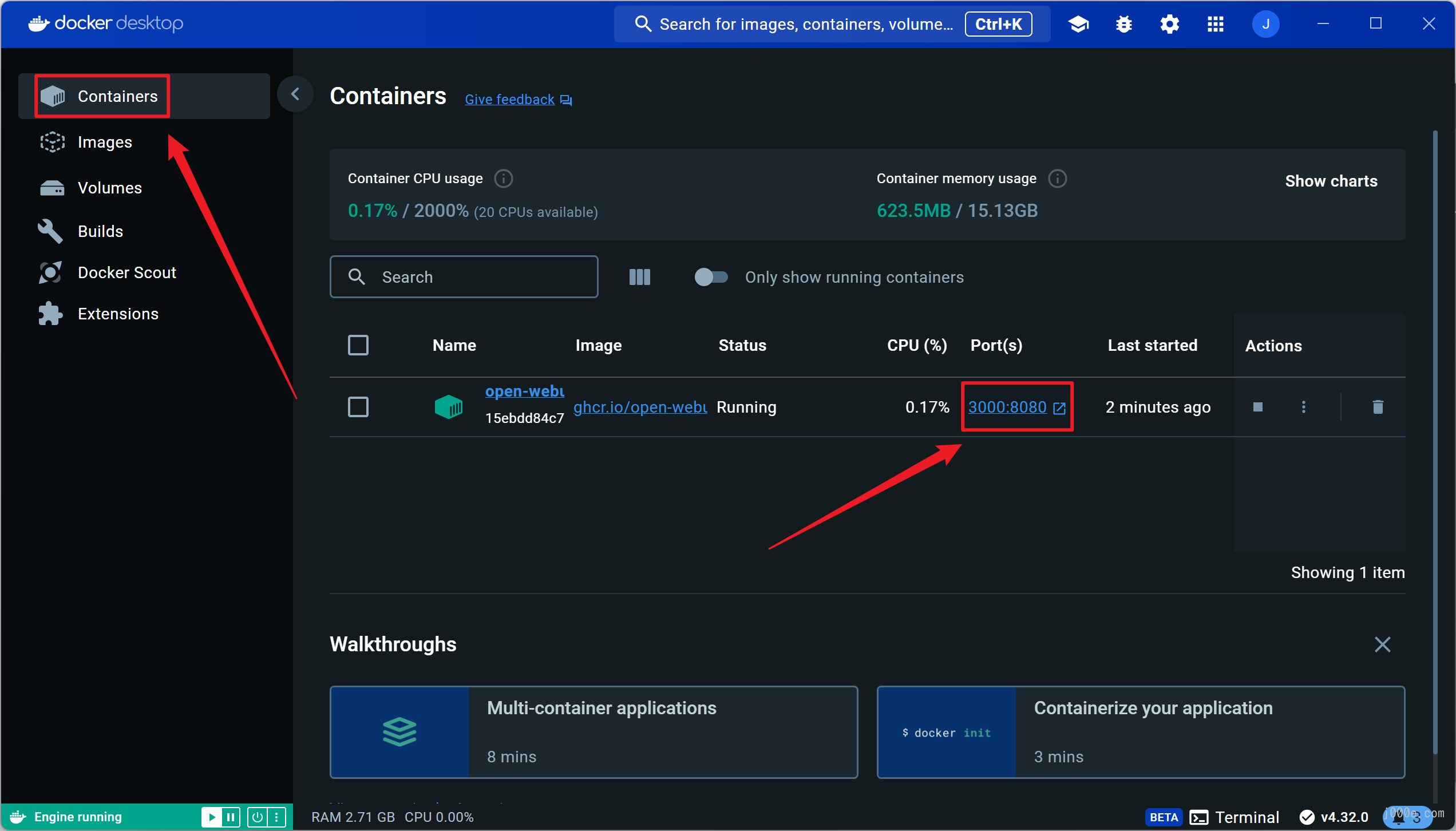
If you see this page, it means you have succeeded. Next, click on "Sign up" to register an account:
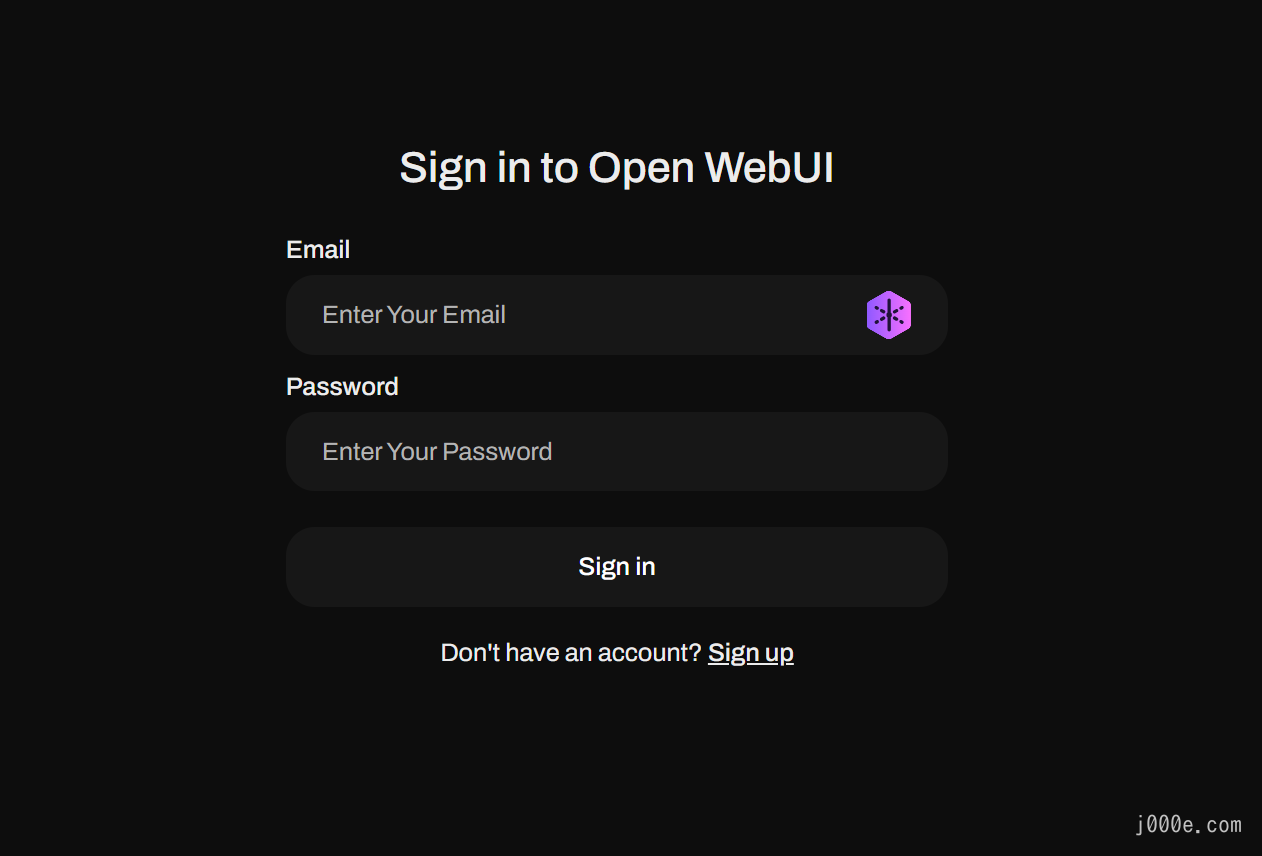
Fill in the information to complete the registration:
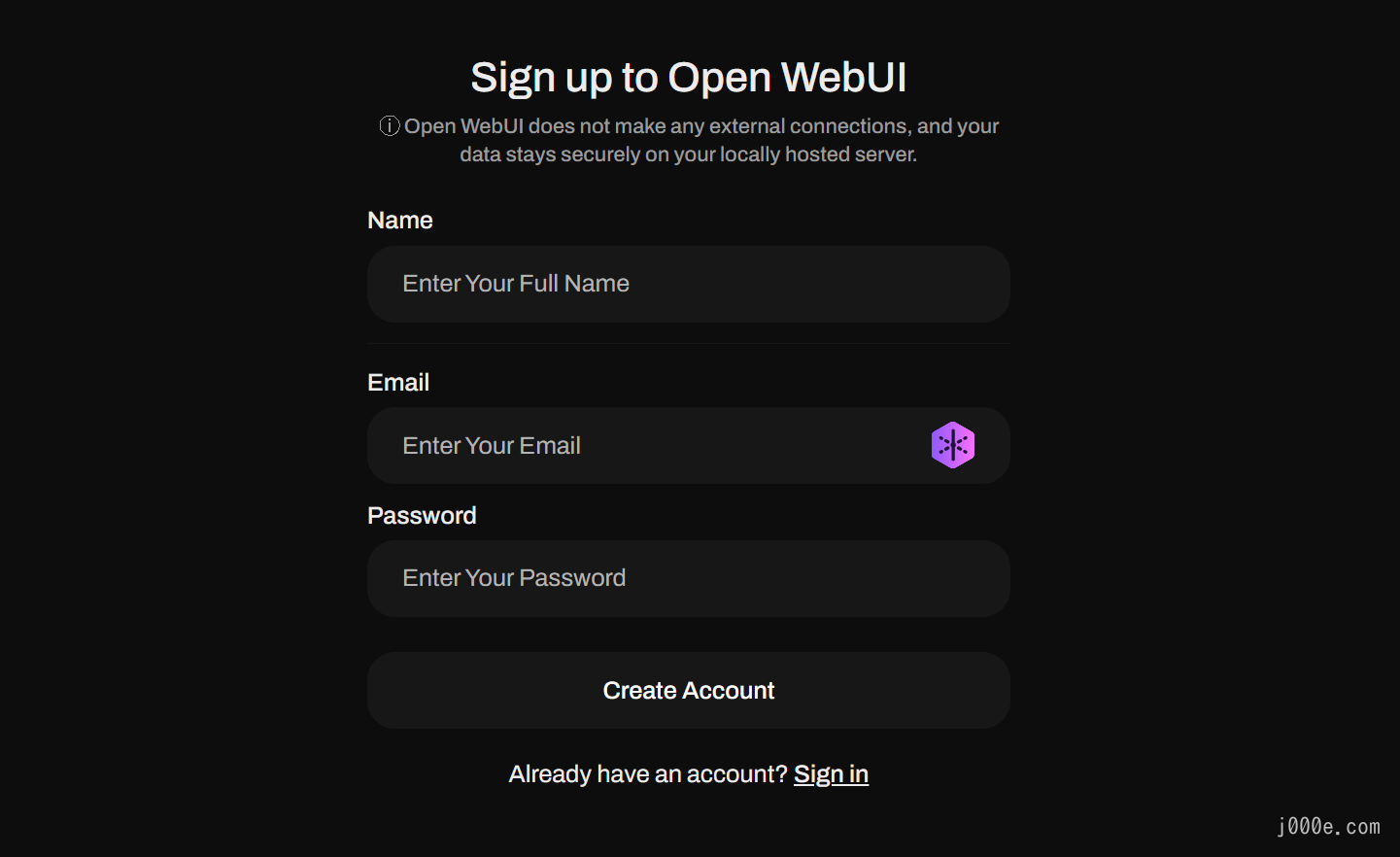
Once logged in, you can select a model from the top left corner. For example, let's choose Llama3:
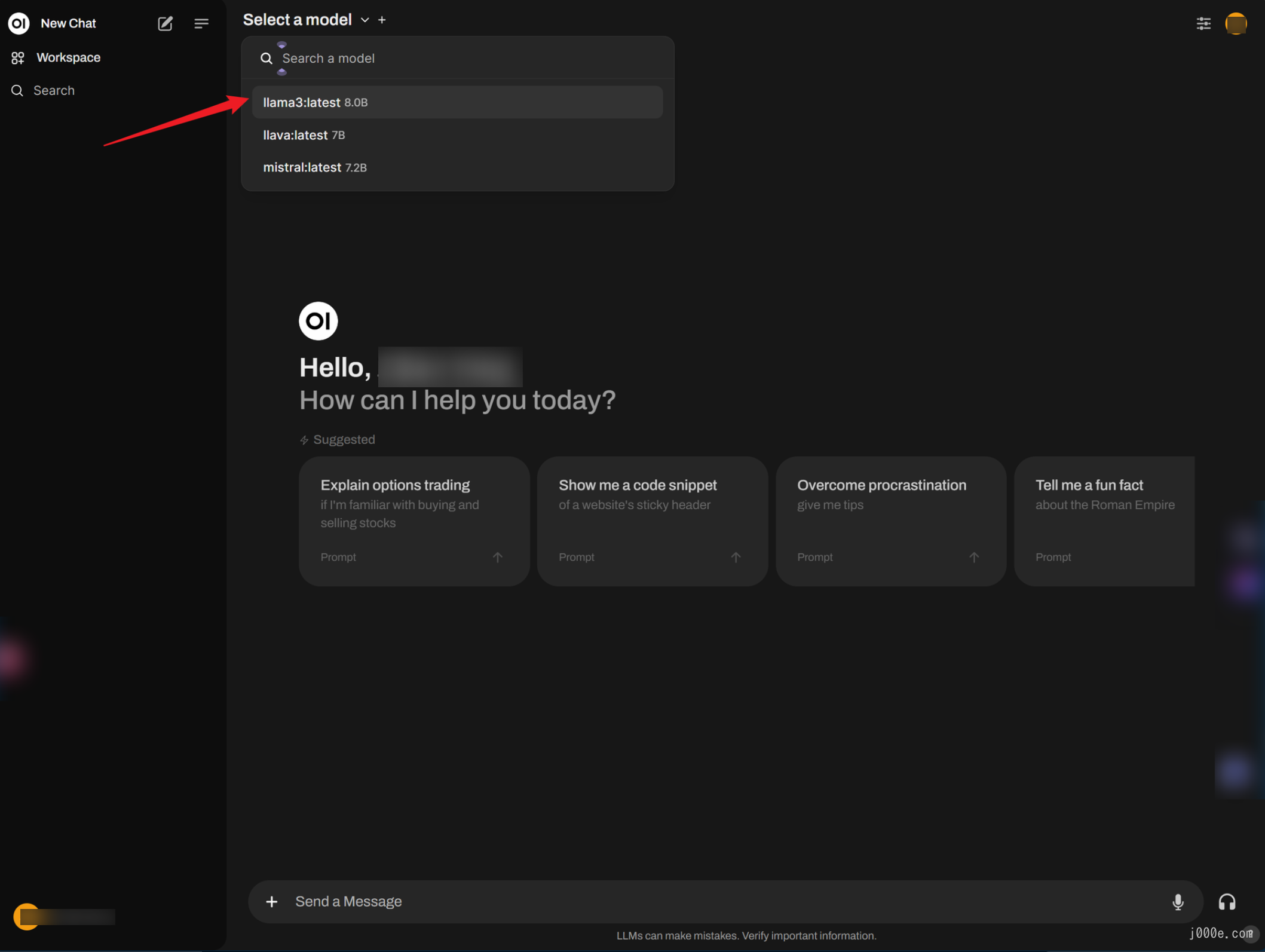
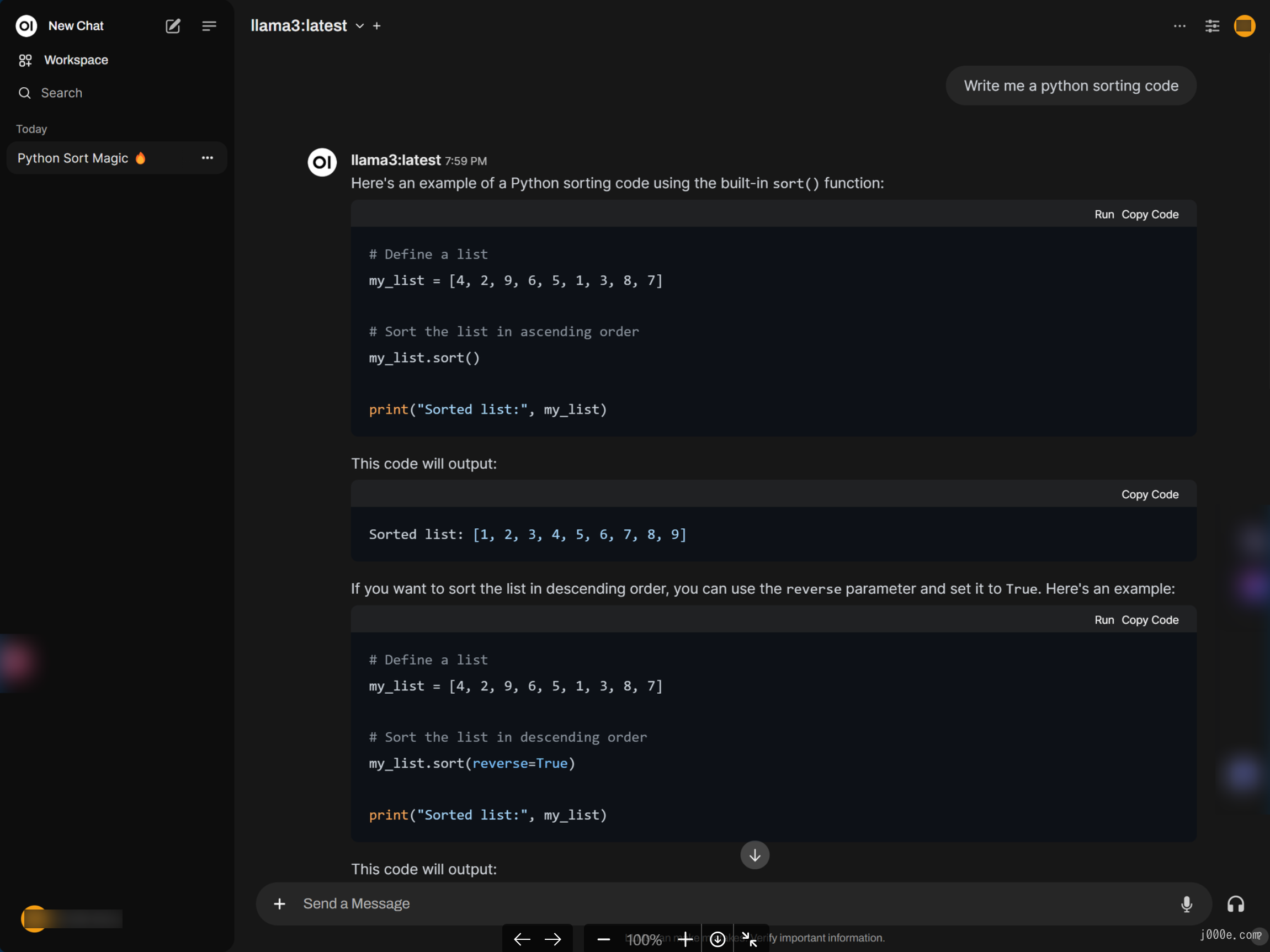
You'll notice that the interface design and interactions are very similar to GPT, making it very user-friendly. It also renders Markdown very well:
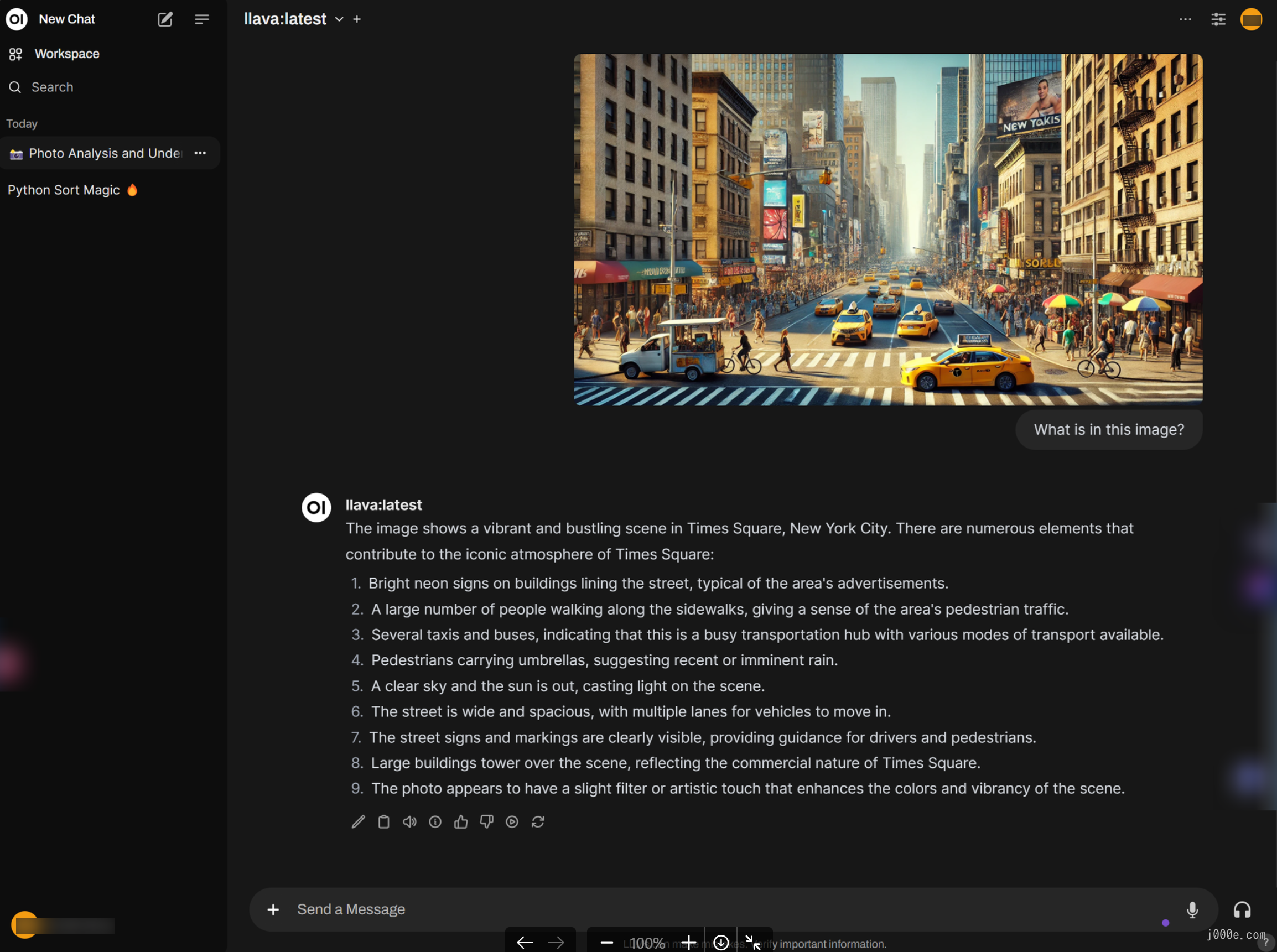
If you choose the LLaVA model, you can directly paste images, which is more intuitive and convenient compared to filling in the path:
At this point, we have completed the deployment of the frontend page. This makes it more convenient and aesthetically pleasing to use, allowing open-source large models to run locally with a perfect user experience.
Conclusion
In this guide, we walked through the process of installing and using Ollama on Windows, highlighting its straightforward setup and powerful capabilities. By following the steps provided, you can easily deploy and manage large language models locally, benefiting from GPU acceleration and ensuring your data remains private.
Ollama simplifies the use of pre-built models like Llama 3 and allows for customization with GGUF models. Additionally, you can explore advanced features such as Docker integration for web-based interfaces, providing a user-friendly chat experience similar to popular AI chatbots.
This guide also touched on customizing prompts and environment variables to suit your specific needs, making Ollama a versatile tool for AI development. With its comprehensive documentation and support for various models, Ollama offers a robust solution for anyone looking to harness the power of large language models.
Through this guide, you should now have a comprehensive understanding of how to use Ollama, and you are ready to embark on your exploration and development journey.
Source
- https://github.com/ollama/ollama
- https://ollama.com/
- https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
- https://github.com/ollama/ollama/blob/main/docs/faq.md#where-are-models-stored
- https://github.com/open-webui/open-webui
- https://www.docker.com/products/docker-desktop/
- https://docs.openwebui.com/
- https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf
One comment
Thank you! Your walkthrough filled in missing information for me that allowed me to install and get this working!